Web Scuffing Vs Crawling: Whats The Distinction? Dev Neighborhood Data crawling services take out duplicate details from the text that might have been copied/pasted, as they can not tell the distinction. In the future, progressed spiders will certainly have the ability to tell the difference. Data scraping is a fantastic technique when you want to remove some information that is challenging to reach, such as commodity prices, as an example. Sometimes, the data winds up being duplicated, as this https://www.mediafire.com/file/a66wtwl80tuui58/179343.pdf/file process isn't developed to exclude the very same data from different resources. Limit your data scratching or creeping frequency and rate to prevent overloading or collapsing the internet servers. Examination and debug your code before running it on the real websites or records, handling any type of errors or exceptions that might occur during the data extraction process. Shop and manage your information in a safe and secure and orderly means with suitable layouts, such as CSV, JSON, or SQL. Also keep in mind to backup your data routinely and erase or archive any type of outdated or pointless information. Information crawling obtained its name from spiders who creep around the facilities. A virtual "spider" can creep around the Net, indexing pages of numerous websites. This process is required to filter and different different types of raw data from different sources right into something useful and insightful. Data scraping is a lot more specific than data abounding what it collects. It can pull things out, such as commodity prices, and more challenging to get to information.
The business of real-time data - is there an ethical approach to web scraping? - diginomica
The business of real-time data - is there an ethical approach to web scraping?.
Posted: Wed, 21 Jun 2023 07:00:00 GMT [source]
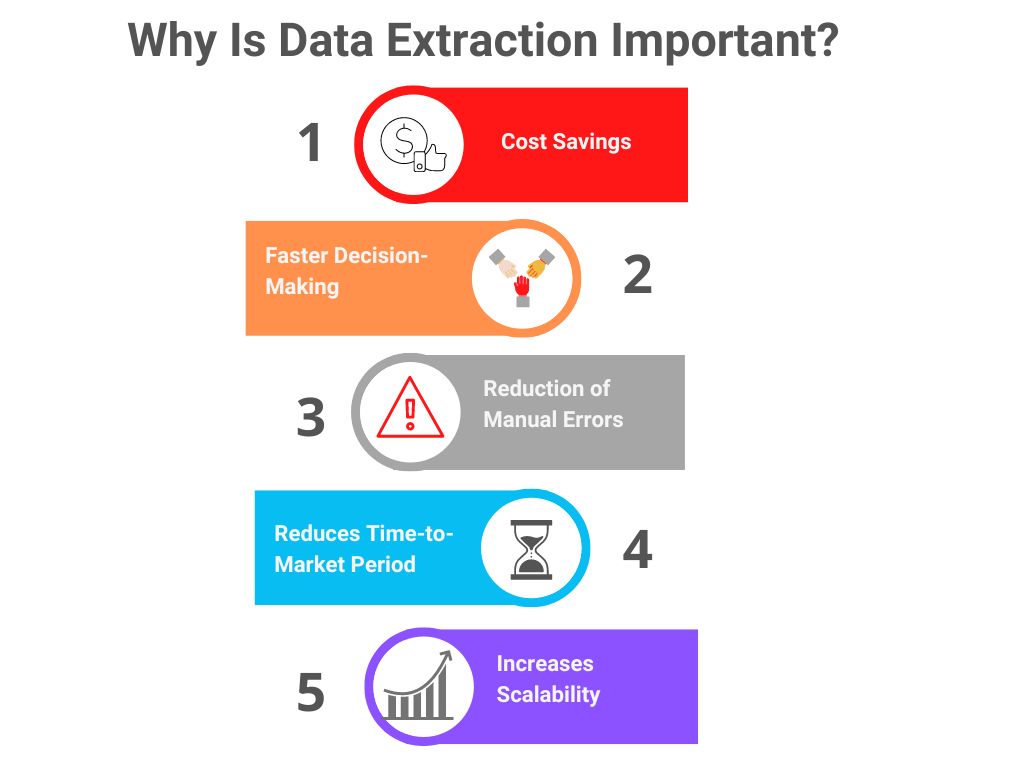
Understanding Javascript Collections: Selections, Sets, Maps, And More
It commonly entails composing code to engage with a website's HTML and remove the wanted info. For example, if you wanted to remove a list of item names and costs from a shopping web site, you can write an internet scrape to do so. Our team of dedicated and dedicated experts is a special mix of strategy, creative thinking, and innovation. Both scuffing and creeping are data extraction methods that have been around for a long time. Depending on your organization or the type of solution you're looking to get, you can select either of the two. It's vital to comprehend that while they could show up the exact same on the surface, the actions included are pretty different.So where are we all supposed to go now? - The Verge
So where are we all supposed to go now?.
Posted: Mon, 03 Jul 2023 07:00:00 GMT [source]
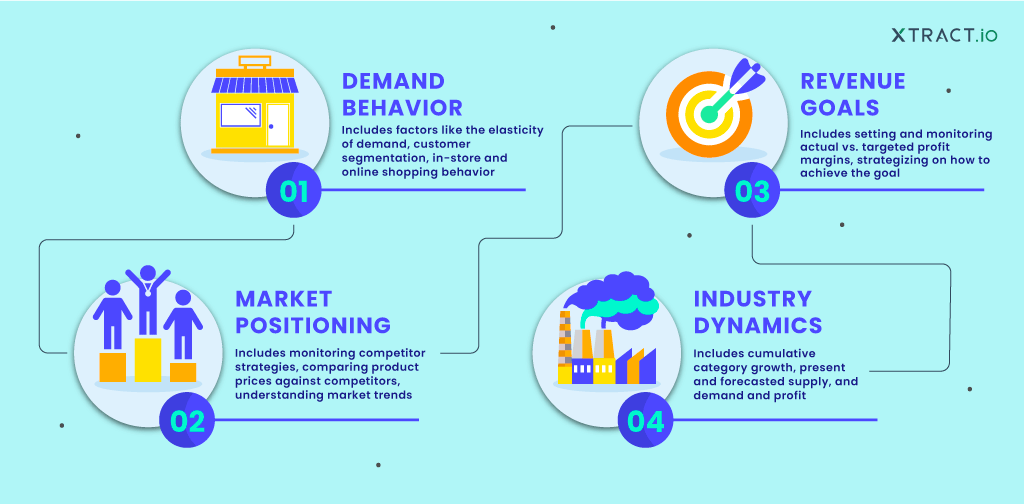
Data Science
Internet scrapers essence particular information collections and can be "anything." It is likewise unneeded for an internet scraper to follow all the web links related to a site. Internet scratching and API are two basic approaches made use of to remove data. While both make the removal process less complicated and automated, each technique works in a different way. Crawling is systematic link collection, while scraping specifies information extraction.- Data scratching is easier to set up, as it can be customized to complete any specific job and overcome any type of prospective obstacles that may take place while doing so.Mentioning changes, all edits users ever before make in a document are saved and available for evaluation.Both web creeping and data scuffing are techniques of retrieving data and the details needed and processes associated with acquiring them.For comprehending the possibility we're talking about here, this is just the pointer of the iceberg.JPEG formats are most common data scratching styles with a long practice and support from every web browser and picture editor on the marketplace.